Introduction
Lambda became very popular amongst modern Apps’ architectures, it’s broadly used to create Cloud Functions on AWS public Cloud.
This article will go over a simple way to create a CI/CD pipeline for Lambda functions whose codes are hosted on GitLab with either ClaudiaJS, Chalice or the ServerlessFramework as an additional automation tool for their management.
The YouTube Channels in both English (En) and French (Fr) are now accessible, feel free to subscribe by clicking here.

Function Management
By managing our functions we mean operations that are performed quite frequently like function creation (in a new region) and deployments to push the newest versions of our code to the Cloud.
ClaudiaJS
For the sake of the demonstration, NodeJS is used as the runtime for our Lambda function and we’ll be using ClaudiaJS as the automation tool to quickly manage it on usual days but depending on the runtime any other tool will do.
By this step, let’s assume you already have a Lambda function created using ClaudiaJS, or you can simply clone ni-microservice-nodejs-gitlabci (a lightweight copy of numerica-ideas/ni-microservice-nodejs) which is powered by ClaudiaJS, the inception details of our sample microservice is being described in the following article.
A few NPM scripts have been put in place in the package.json file to quickly manage the function by running some commands that perform the desired operations by using ClaudiaJS underneath:
npm run create: to create our lambda on the AWS side, to be done once after configuring the environment variables described below.npm run deploy:devornpm run deploy:prod: these scripts push a new version of the function respectively for development and production environments.npm test: runs the unit tests that are part of the pipeline executions.- The deployment flow being illustrated uses a private S3 bucket named ni-deployments (to be changed in the package.json file) that keeps the latest deployment artifact as new versions are shipped.
The traditional npm install will always install dependencies in a NodeJS project as soon as the package.json file is provided.
For a better separation of our environments, we opted to have two more files dev.json & prod.json respectively for the development and production Lambda deployments, these are ignored by git as the default .env file used for traditional server deployments.
Two private buckets should be created to have these saved differently since in a production setup it’s often designed that way to enable a more flexible and secured permissions management for users/services:
- Development: ni-variables-dev
- Production: ni-variables-prod
Once our environment JSON files are ready we can use the following commands to have these pushed to our S3 storage:
npm run set-vars:devnpm run set-vars:prod
The content of the production one (prod.json) could look like the one below, for the sake of the example we only have NODE_ENV and PORT variables:

During the pipeline executions, our CI/CD flow uses these files to pull the right variables depending on the environment, so the dev deployment script uses the commands npm run get-vars:dev to have the dev env variables (get-vars:prod for the production one).
Let’s make sure to create the function on the AWS side using the npm run create command, which creates a claudia.json file and prints to the console like the following screenshot:

For now, let’s limit ourselves to these three scripts since we should only cover the CI/CD side and even to a minimal extent. This article is not about mastering ClaudiaJS tool, if you are looking at other possibilities that it provides feel free to take a look at the corresponding documentation.
Serverless Framework / Chalice
ClaudiaJS does a claudia update --version env by using the npm run deploy env command, which is replicable regardless of the management tool being used.
The same NPM deployment script will have sls deploy --stage env as value if the ServerlessFramework were used or even chalice deploy --stage env if Chalice was at the center of a function created using the Python runtime.
Note: env represents the environment (profile) we are deploying to, it could be dev, prod, or anything else.
Are you looking further? Feel free to read the following article if you are interested in boosting the performance of your Lambda function.

CI/CD Pipelines
It now become a common practice to keep the source code as close as possible to the CI/CD provider for faster deliveries, and it happens that GitLab is doing both at the same time, so it’s possible to use it not only as a code hosting platform but also to automate build, test and deploy processes as part of the CI/CD mechanism.
Setup
Using GitLab CI/CD is very simple as it’s done by creating the .gitlab-ci.yml configuration file that resides at the root (default location) of the repository you cloned a few steps ago, if it’s missing then no pipelines will run.
Once created, GitLab detects it and an Application called GitLab Runner will run your pipelines’ jobs as commits occur.
From the official documentation page that specifies how this configuration file should be created, it’s said that:
The scripts are grouped into jobs, and jobs run as part of a larger pipeline. You can group multiple independent jobs into stages that run in a defined order. The CI/CD configuration needs at least one job that is not hidden.
In our case, three (3) stages (build, test, and deploy) have been created to perform our operations; in which we have dependencies, testing, dev_deployment, and prod_deployment Jobs.
Here’s how the Pipeline Architecture looks like:

Build Stage
First, we build the App by installing dependencies and compiling TypeScript files to JavaScript ones as follows:
dependencies:
stage: build
script:
- npm install
- npm run build
artifacts:
paths:
- node_modules/
only:
- master
- develop
Test Stage
Then, the unit tests are run using the AVA test runner abstracted by npm test command:
testing:
stage: test
script: npm test
only:
- master
- develop
Deploy Stage
Finally, the deployment happens depending on the branch involved. At the moment, we have two distinct deployment jobs respectively for develop and master branches while build and test ones are the same for both:
# Development deployment job
dev_deployment:
stage: deploy
only:
- develop
script:
- apt-get update -y
- curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
- unzip -u awscliv2.zip
- ./aws/install
- rm -rf awscliv2.zip
- aws --version
- npm run deploy:dev
# Production deployment job
prod_deployment:
stage: deploy
only:
- master
script:
- apt-get update -y
- curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
- unzip -u awscliv2.zip
- ./aws/install
- rm -rf awscliv2.zip
- aws --version
- npm run deploy:prod
Let’s note that these can be abstracted even more to centralize common tasks.
The full configuration file is available on GitHub.
Pipelines Executions
There are multiple options to trigger pipeline executions, the most common is via Jobs created by actions made on the repository (commit, release/tag … etc) which this article covers a few more lines down.
Once pushed the first commit with the configuration file (.gitlab-ci.yml) in place, the pipeline was executed and a full summary was printed a few minutes later in the repository Pipelines area, it looked like the following screenshot:

As expected, the build (NPM dependencies installation and TypeScript compilation) and test (sample OK tests provided) stages succeeded while the deploy one failed; which is normal since we are deploying using ClaudiaJS (or any alternative) which communicates with AWS while GitLab doesn’t know yet how to interact with our AWS infrastructure which we dive deep on in the next section.
AWS Credentials
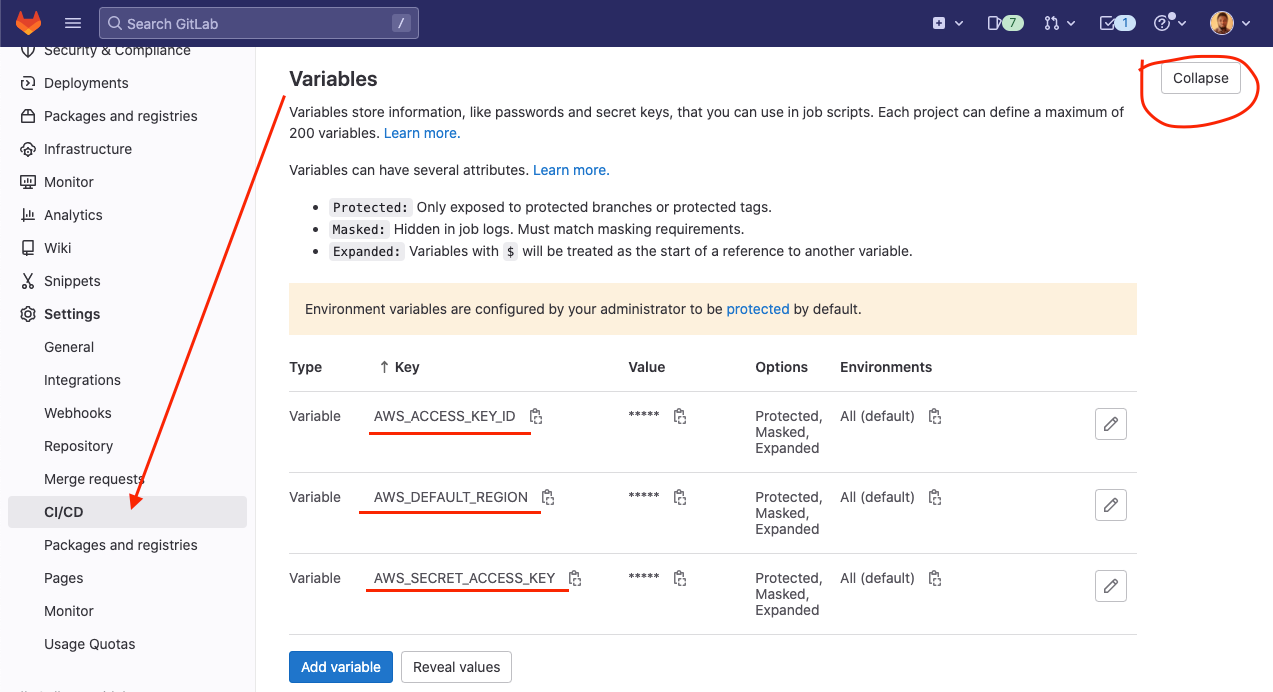
GitLab has predefined CI/CD variables used by AWS tools for deployments and/or resource management, from the repository settings you can define these variables.
The UI is straightforward and looks like the below where we simply have to specify the right key and value in the first two inputs:

Let’s perform this multiple times to specify the AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY & AWS_DEFAULT_REGION variables:
Once done, feel free to make a small change and then a commit to see the pipeline getting triggered once more, now we have successes for the build, test, and deploy stages as you can see:

The Pipelines History is also available on this public GitLab Page for you to have a closer look at.
Let’s note that the free plan of GitLab allows us 400 minutes of runner executions per month, while you are free to create your runners or take advantage of the SASS option by subscribing to an upper package. So it’s a good idea to always use a base Docker image that contains everything you need, since installing stuff manually will cost you pipeline minutes.
———————
We have just started our journey to build a network of professionals to grow even more our free knowledge-sharing community that’ll give you a chance to learn interesting things about topics like cloud computing, software development, and software architectures while keeping the door open to more opportunities.
Does this speak to you? If YES, feel free to Join our Discord Server to stay in touch with the community and be part of independently organized events.
———————
Conclusion
For speed and quality purposes, it’s very important to consider it as a release practice to design a CI/CD pipeline for your Apps’ components, let’s note that the tinier/segmented your components are the easier the pipelines will be and so for most of the cases you will not need a Release Manager/Captain in your team anymore.
Thanks for reading this article. Like, recommend, and share if you enjoyed it. Follow us on Facebook, Twitter, and LinkedIn for more content.











